Introducing RelayPlane
Last November I woke up to a problem. I run 10+ AI agents for pretty much everything in my business. Code generation, content drafting, lead research, PR reviews, security audits. All hitting the Anthropic API, all configured to use Claude Opus because I wanted the best output.
My monthly bill was $340. And I couldn't tell you where half of it went.
One agent had gotten stuck in a retry loop overnight. Another was using Opus to read file headers and check git status. Tasks that a model ten times cheaper handles identically. But every agent had the same API key, the same model, the same “just send it” logic. There was no layer between the agents and the providers. No visibility. No controls. Just API keys and invoices.
So I built one.
What RelayPlane does
RelayPlane is a local proxy that sits between your applications and your LLM providers. All your API traffic flows through it. In exchange, you get three things you didn't have before:
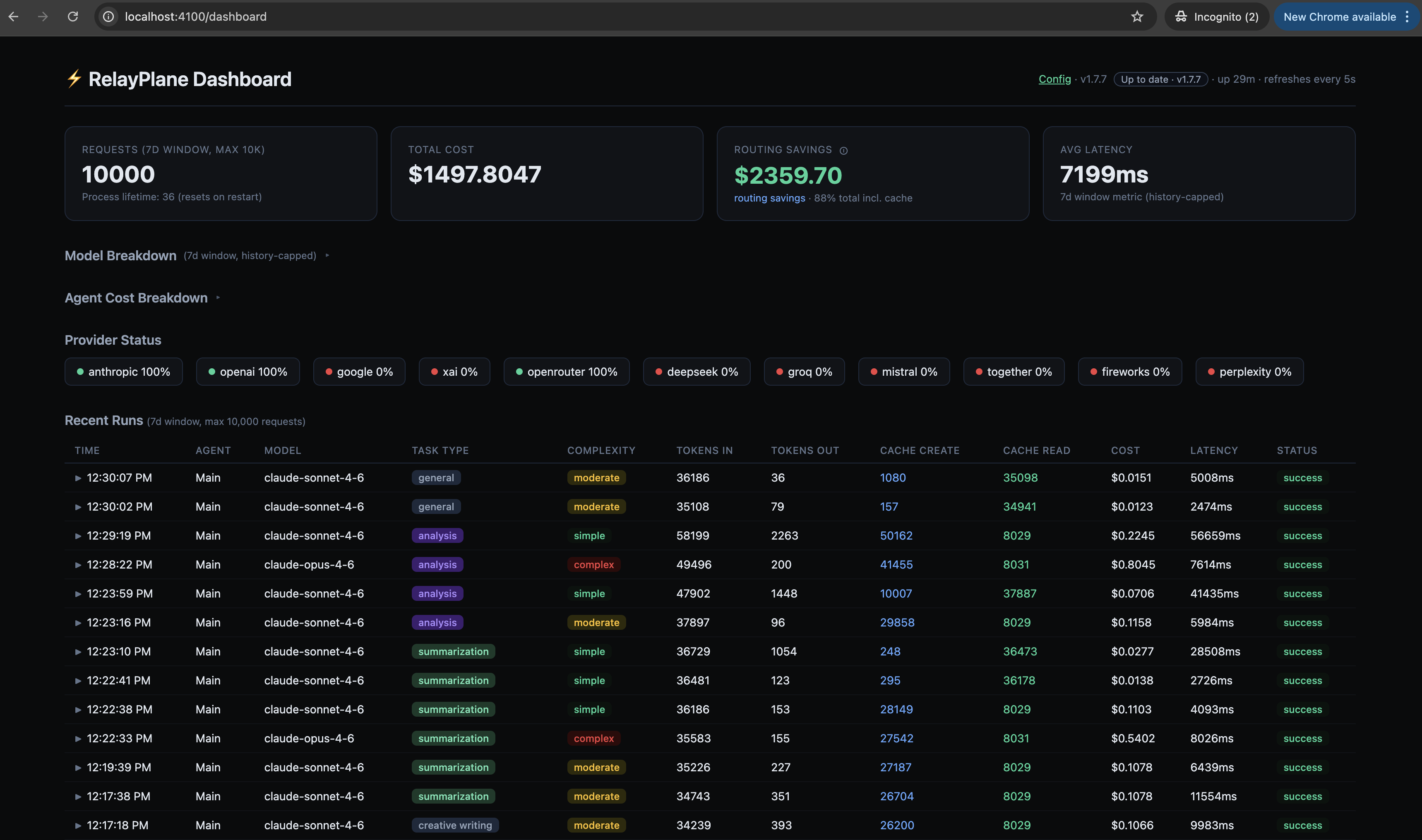
Cost tracking on every request. Not aggregated on a billing page days later. Per-request, per-model, per-agent. You see exactly what each call cost the moment it completes. When something looks wrong, you know immediately instead of discovering it on the invoice.
Routing by complexity. You define rules once. Simple tasks (summarization, formatting, file reading) go to cheaper, faster models. Complex reasoning and code generation stay on the flagships. Your agents don't change. The proxy handles it. How much you save depends on your workload. Heavy coding and complex reasoning? Maybe 30-40%. Mostly chat, doc review, and data extraction? Closer to 80%. Either way, you stop paying flagship prices for tasks that don't need a flagship model.
Cascade fallback across providers. When Anthropic rate-limits you at 2am, RelayPlane falls back to OpenAI or Gemini automatically. Your agents don't crash. They don't queue up and retry the same dead endpoint. Traffic shifts, work continues, you deal with it in the morning.
Why a proxy
My first instinct was to add cost tracking inside each application. Wrap the API calls, count tokens, log it somewhere. Then I remembered I was running a dozen different services. Adding tracking to each one meant maintaining the same logic in a dozen places, updating it every time a provider changed pricing, and hoping I didn't miss one.
The proxy approach means you handle it once. One process, one config, all traffic flows through it. This is the same pattern we use for databases (connection poolers), for HTTP (reverse proxies), for auth (API gateways). AI APIs are just another service where the direct connection works until it doesn't.
npm install, that's it
This was a deliberate choice. Most AI infrastructure tools want you to spin up Docker containers, manage Python virtual environments, or download Go binaries. I didn't want any of that. I wanted something I could install on a fresh machine in one command and have running in under a minute.
npm install -g @relayplane/proxy
relayplane init
relayplane startThat gives you a proxy on localhost:4100 with a built-in dashboard. Single Node.js process. No containers. No system dependencies beyond Node itself. It runs on a Raspberry Pi, a $5 VPS, or whatever you're developing on right now.
The init command walks you through provider setup. You paste in the API keys you already have. Nothing gets sent anywhere except directly to the providers you configure.
11 providers, plus Ollama
Direct integrations with Anthropic, OpenAI, Google Gemini, xAI, OpenRouter, DeepSeek, Groq, Mistral, Together, Fireworks, and Perplexity. Not through an intermediary. Your keys, your accounts, direct connections.
And then there's Ollama. If you're running local models, RelayPlane auto-detects your Ollama instance on localhost:11434 and routes to it. No API key needed. The cost shows up as $0.00 in your dashboard. Every local inference is money not spent on an API call.
I use this daily. Quick lookups and simple tasks go to a local Llama model. Complex code review goes to Sonnet. The agents don't know the difference. The proxy handles the routing.
Built for agents, not chatbots
Most LLM proxies are built for chat applications. A human sends a message, gets a response, maybe sends another. Agent workflows are different. Agents send hundreds or thousands of requests per day. They run overnight. They spawn sub-agents that spawn more sub-agents. A single stuck loop can burn through your daily budget in an hour.
RelayPlane was built for this from the start:
Budget enforcement. Set daily, hourly, or per-request spending limits. When a limit is hit, the proxy blocks the request and returns a clear error. The agent can handle it gracefully instead of burning tokens on a 500 error retry loop.
Anomaly detection. If an agent suddenly starts making 10x its normal request volume, RelayPlane flags it. You can configure it to alert, throttle, or hard-block.
Circuit breakers. When a provider starts returning errors, the circuit opens and traffic shifts to the next provider in the cascade. No thundering herd. No retry storms.
Response caching. Identical requests (same prompt, same model, same parameters) get cached responses. This matters more than you'd think when agents re-read the same context repeatedly.
What it costs
The free tier is unlimited. No request caps. No usage limits. Full local dashboard with 7 days of history. MIT licensed. You can run it forever without paying anything.
The proxy is MIT-licensed and free. Every feature ships in the open-source package: all 11 providers, Ollama routing, budget enforcement, cascade fallback, 90-day history, and team dashboards. No paywalls, no tiers.
You're paying your providers directly. RelayPlane doesn't touch your API traffic beyond routing it. No markup on tokens. BYOK (bring your own keys) only.
The actual numbers
Before RelayPlane: $340/month across providers. No per-agent breakdown. No idea which tasks were expensive. Occasional surprise bills from agent loops.
After: I can see exactly where every dollar goes. Budget caps catch runaway loops before they get expensive. The simple tasks that were burning money on Opus now route to cheaper models automatically. My bill dropped significantly, but the exact savings depend on the month and what the agents are working on. Heavy coding sprints save less. Weeks with a lot of research and content work save more.
The point isn't a magic number. It's that you can finally see what's happening and control it. Agent costs can get out of hand fast when you're running 10+ of them 24/7. Visibility alone changes the game.
Getting started
npm install -g @relayplane/proxy
relayplane init
relayplane startPoint your agents at localhost:4100 instead of the provider API directly. Everything else stays the same. OpenAI-compatible API, so most tools and SDKs work without modification.
The dashboard at localhost:4100/dashboard shows you what's happening in real time. Requests, costs, routing decisions, cache hits, budget status. All local, nothing phoning home.
RelayPlane is open source. MIT licensed. Built because I needed it, and I figured other people running agents probably needed it too.
If you've been running agents without knowing what they cost, try it for a week. You'll be surprised where the money actually goes.