Pillar 1 · ObserveShipped
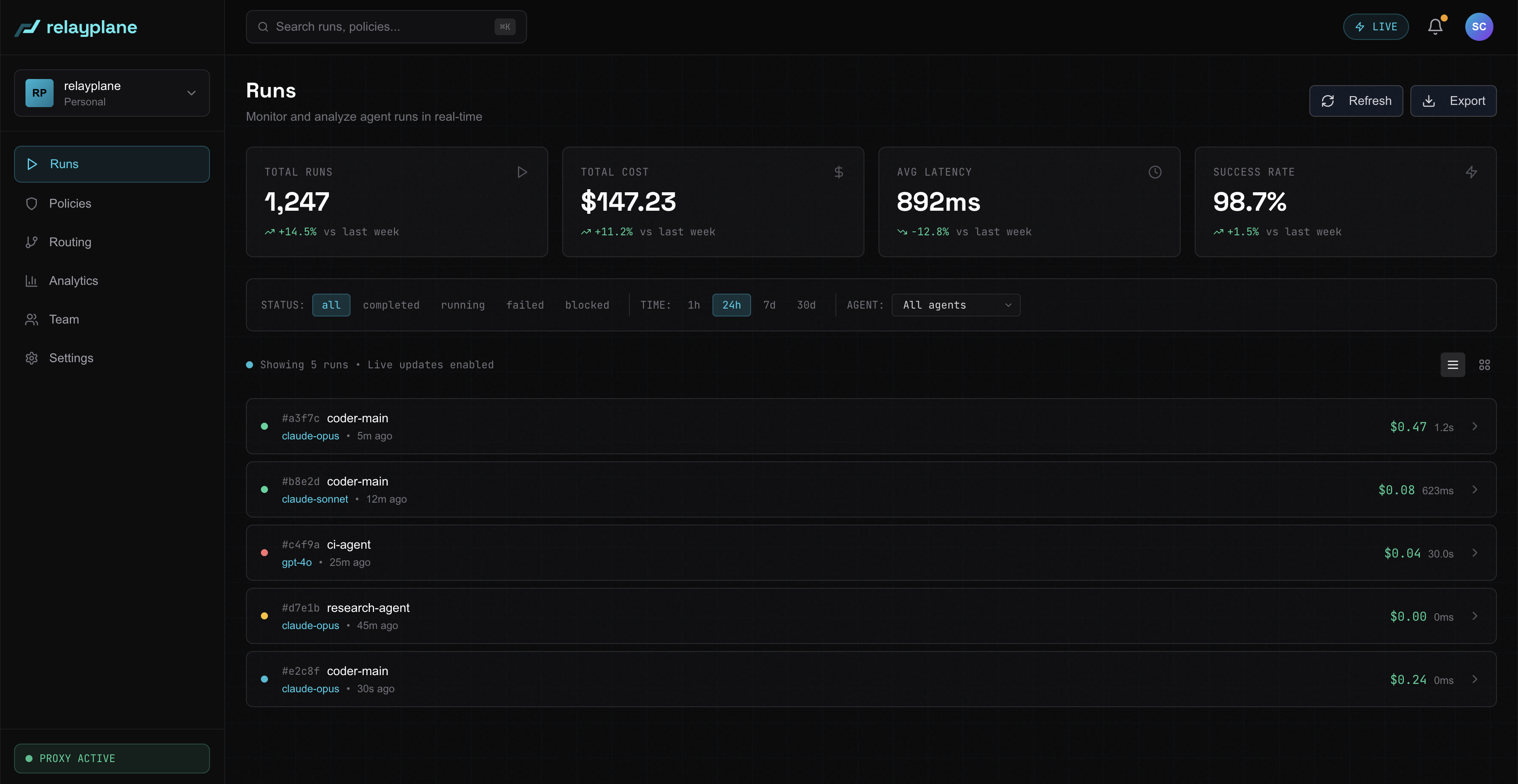
See everything, per agent.
Every LLM request flows through the proxy with full attribution. Cost, model, task type, tokens, latency, all live, all namespaced. Per-agent breakdown uses the system-prompt fingerprint, no annotation work required.
- Per-tenant and per-agent cost tracking
- Cache-aware accounting (Anthropic prompt caching)
- Tamper-proof, exportable audit trail
- 7 days free, 30 days Starter, 90 days Pro, unlimited Max